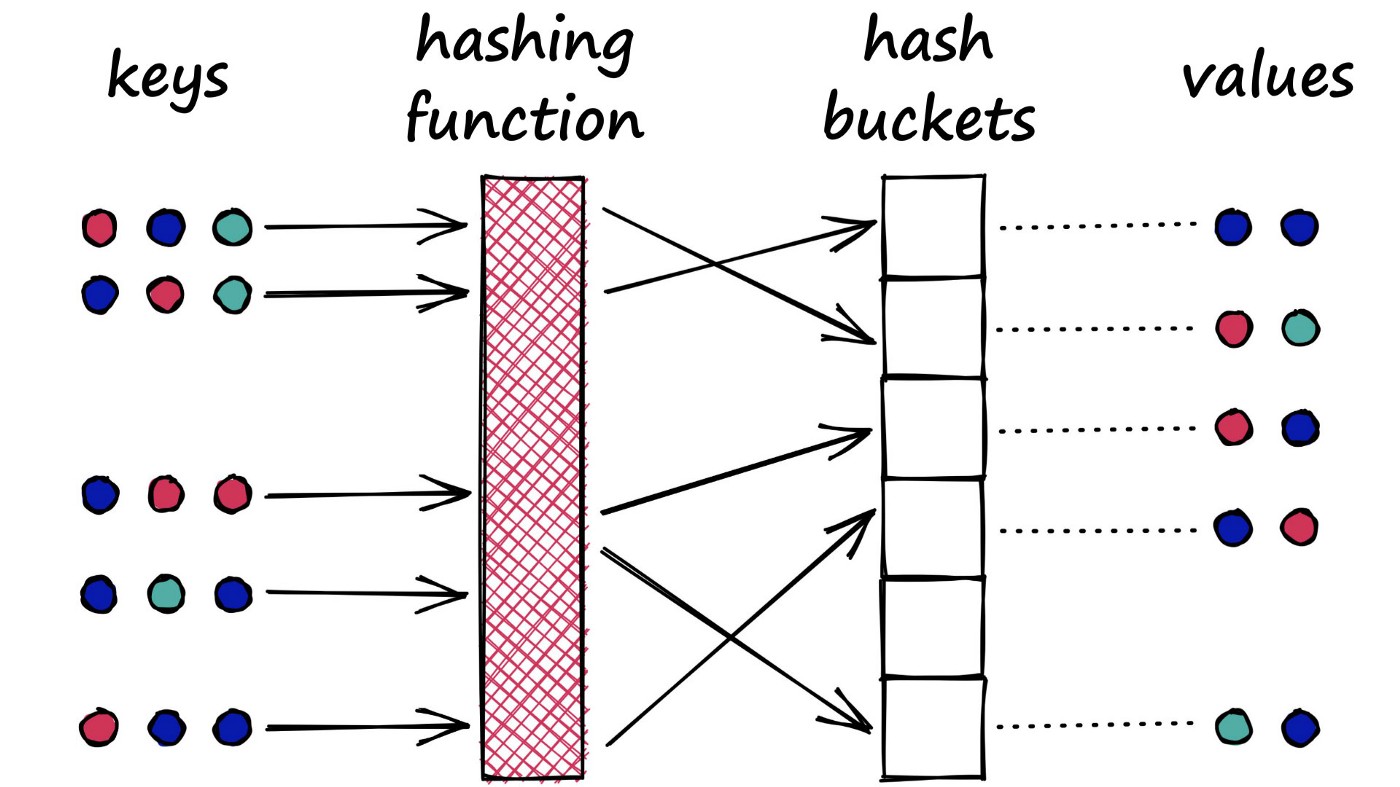
As I am interating over the API design and the implementation of kelindar/column, I’ve started to build some toy examples. One of such toy examples I wanted to explore is how one might go about building a key-value cache using columnar storage.
Now, let me first start by saying that doing this is not efficient and you are probably better off using a traditional key-value store organised as a B+Tree or a Hashmap, in fact, you’d be better of just using map[string]string than using the columnar store.
However, for the sake of the challenge, I’ve implemented one without using any hashmaps or b-trees and using exclusively bitmaps. In fact, I used one bitmap per index and one for a bloom filter. This code is kept simple on purpose and hence is not the most efficient one and there can be a ton of improvement. Doing this gave me some ideas on what to improve in column to make this use-case a bit more performant and easier to implement.
Implementation
Three columns are created on the collection key for the key string itself, val for the string value to be cached and crc for the checksum/hash value of the key.
db := column.NewCollection()
db.CreateColumn("key", column.ForString())
db.CreateColumn("val", column.ForString())
db.CreateColumn("crc", column.ForUint64())
On top of crc column we create a number of bucket indices, in this example 100 buckets are created. Basically it functions as a transposed hash table when you think about it, but in this implementation the bucket size will vary - more items will result in larger buckets and larger search for the key. It’s not ideal, but interesting for the sake of the exercice.
for i := 0; i < buckets; i++ {
bucket := uint(i) // copy the value
db.CreateIndex(strconv.Itoa(i), "crc", func(r column.Reader) bool {
return r.Uint()%uint(buckets) == bucket
})
}
Next, we also create a bitmap to act as a bloom filter. This allows us to quikcly check if a single key is present in the collection or not, and quickly skip search if it does not exist. It’s helps to make the insertion not too slow for large numbers of elements stored in the cache.
func (c *Cache) addToFilter(hash uint32) {
position := hash % uint32(len(c.bloom)*64)
c.bloom.Set(position)
}
func (c *Cache) checkFilter(hash uint32) bool {
position := hash % uint32(len(c.bloom)*64)
return c.bloom.Contains(position)
}
The search function is expressed with a single transaction. It computes the bucket, narrows down the search to the bucket using the bitmap index with the same name, then does a linear search within it to compare the hash. Once found, it selects the value and the index.
// Get attempts to retrieve a value for a key
func (c *Cache) Get(key string) (value string, found bool) {
hash := crc32.ChecksumIEEE([]byte(key))
value, idx := c.search(hash)
return value, idx >= 0
}
// search attempts to retrieve a value for a key. If the value is found, it returns
// the actual value and its index in the collection. Otherwise, it returns -1.
func (c *Cache) search(hash uint32) (value string, index int) {
index = -1
c.store.Query(func(txn *column.Txn) error {
bucketName := fmt.Sprintf("%d", hash%uint32(buckets))
return txn.
With(bucketName).
WithUint("crc", func(v uint64) bool {
return v == uint64(hash)
}).Range("val", func(v column.Cursor) {
value = v.String()
index = int(v.Index())
})
})
return
}
On the flip side, when you want to insert the key we simply check the bloom filter, and if it exists we perform a search and update the value if found. Otherwise, we add to the bloom filter and insert a new row.
// Set updates or inserts a new value
func (c *Cache) Set(key, value string) {
hash := crc32.ChecksumIEEE([]byte(key))
// First check if the value already exists, and update it if found.
if c.checkFilter(hash) {
if _, idx := c.search(hash); idx >= 0 {
c.store.UpdateAt(uint32(idx), "val", func(v column.Cursor) error {
v.SetString(value)
return nil
})
return
}
}
// If not found, insert a new row
c.addToFilter(hash)
c.store.Insert(map[string]interface{}{
"key": key,
"val": value,
"crc": uint64(hash),
})
}
Some Results
Below are some results for the cache, it first populates 50,000 items, which is kind of slow. Then, does 10 random searches and measures it. Here, since we have 100 buckets and 50,000 items the search would produce around 500 elements per retrieval, after the binary AND operation.
inserting users...
-> inserted 10000 rows
-> inserted 20000 rows
-> inserted 30000 rows
-> inserted 40000 rows
-> inserted 50000 rows
running query of user_26610...
Hi, User 26610 true
-> query took 8.656µs
running query of user_24331...
Hi, User 24331 true
-> query took 9.01µs
running query of user_3037...
Hi, User 3037 true
-> query took 9.028µs
running query of user_11939...
Hi, User 11939 true
-> query took 8.516µs
running query of user_17105...
Hi, User 17105 true
-> query took 8.255µs
running query of user_21641...
Hi, User 21641 true
-> query took 9.183µs
running query of user_2246...
Hi, User 2246 true
-> query took 8.885µs
running query of user_39395...
Hi, User 39395 true
-> query took 9.156µs
running query of user_15154...
Hi, User 15154 true
-> query took 8.983µs
running query of user_8555...
Hi, User 8555 true
-> query took 8.75µs
Conclusions
So here you have it, a columnar store without any hashmaps used to build a key-value store. Once again, this is just for the sake of intellectual challenge and not really to be used in production, or anything like this. However, I’ve gotten a couple of ideas:
- It might be useful to implement an automated way of bucketing/indexing a value in multiple bitmaps which could potentially speed up the
Set()in this use-case, as currently when adding1value, it not only does a search, but also computes100bitmap indices, and 99 of them will be unchanged. - There’s no real reason why one wouldn’t want to use
map[string]uint32or any other hash table as a primary key to offset lookup table. In fact, this makes sense in a lot of applications and I will probably try to implement theCreatePrimaryKey()function on the collection at some point in future.